
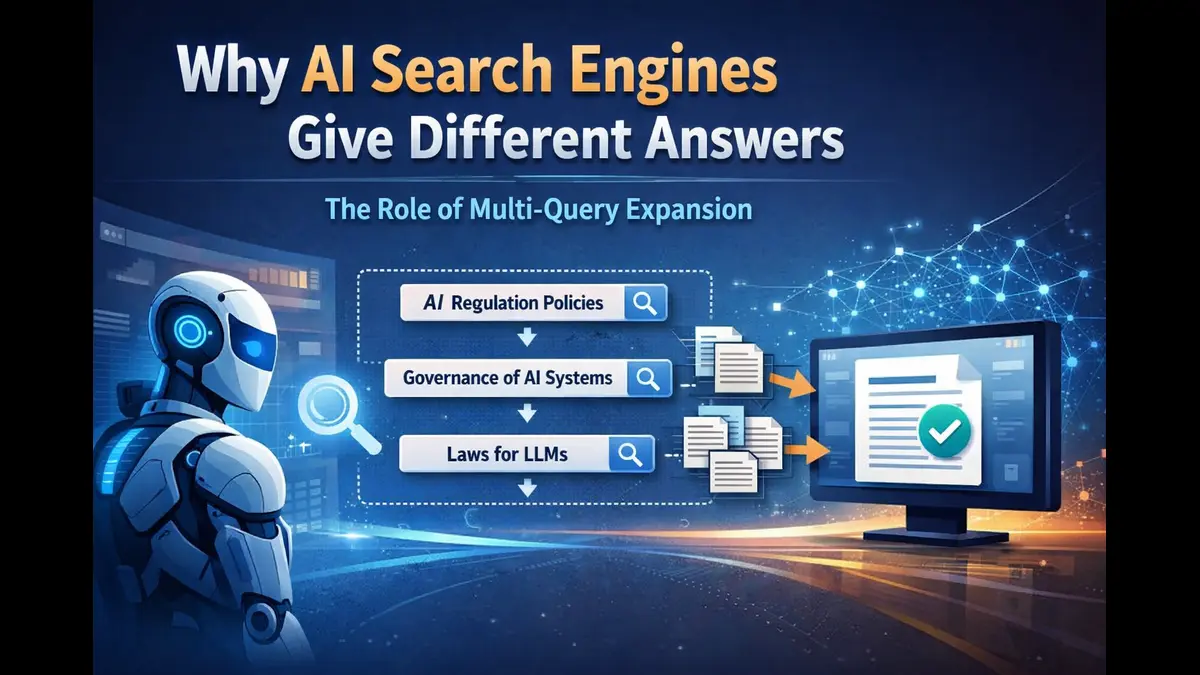
Modern AI search engines rely on complex retrieval pipelines before generating answers. One important technique used to improve search coverage is multi-query expansion, which generates multiple query variations to retrieve more relevant information.
You’ve probably experienced this before. You ask the same question to an AI search engine twice — sometimes only minutes apart — and the answers feel slightly different. One response might emphasize a specific study, while the other highlights a different perspective or set of sources. It’s tempting to blame it on “AI randomness” or temperature settings, but the real variation often begins much earlier.
Modern AI search engines are far more than just powerful language models. Most modern systems use a Retrieval-Augmented Generation (RAG) architecture, where external information is retrieved first and then used to ground the model’s response. The quality of the final answer depends heavily on what the retrieval stage manages to surface. And one of the most persistent challenges in that stage is the query mismatch problem — the gap between how we phrase our questions and how relevant information is actually written online.
In this article we explore here why this problem exists, why it matters more than most people realize, and how forward-thinking AI search systems today are solving it through a smart technique called multi-query expansion.
The Retrieval Problem Most Users Never Notice
Traditional search engines still rely heavily on matching keywords. Techniques like BM25 analyze term frequency and rarity to rank documents. It works reasonably well when the query and the source material use very similar wording.
But human language is naturally flexible. The same idea can be expressed in countless valid ways.
A question about “remote work productivity” might appear in articles as “distributed team performance,” “asynchronous collaboration effectiveness,” “virtual workforce output metrics,” or “managing knowledge workers in remote environments.” Even though these all refer to the same concept, a single rigid query can easily miss large portions of relevant content.
This is the query mismatch problem. Valuable documents exist, but because they use different phrasing or framing, they never make it into the initial results. The language model then has to generate an answer based on an incomplete picture. Users don’t see the retrieval step — they only notice when answers feel narrow, inconsistent, or surprisingly different on repeat asks.
Multi-Query Expansion: Casting a Wider Net
The solution many advanced systems use is called multi-query expansion.
Instead of searching with just the user’s original question, the system intelligently generates several alternative phrasings that capture the same underlying intent. For a query about “AI regulation,” it might also search for “artificial intelligence governance frameworks,” “regulatory policies for large language models,” or “legal oversight of generative AI systems.”
These aren’t random rewrites. They are purposeful variations designed to explore different linguistic pathways into the topic. The system then runs parallel searches, gathers results from all versions, removes duplicates, and intelligently merges them.
Crucially, the original question is never changed — the expansions simply help uncover documents that a single phrasing might have missed.
How Multi-Query Expansion Fits into the Bigger Picture

In a well-architected AI search system, multi-query expansion plays a key early role. A typical pipeline begins with query understanding, where the system classifies the intent, complexity, and required search depth. For anything beyond a simple lookup, it then generates two to four alternative phrasings of the original query.
Each version is sent for parallel retrieval using both traditional keyword search and modern semantic (embedding-based) methods. The results are merged, with the system carefully tracking which documents appear across multiple query versions. These overlapping sources often receive a relevance boost during reranking, which scores documents based on relevance, source trustworthiness, freshness, and cross-query signals.
The top content is then enriched and compressed into a concise context window before being passed to the large language model for final answer generation. Because expansion happens so early, it positively influences every later stage — leading to better coverage, stronger reranking, and ultimately more balanced, well-grounded answers.
Why Retrieval Architecture Actually Matters More Than Model Size
There’s plenty of attention on bigger, smarter language models — and rightfully so. But even the most capable model is limited by the information it receives.
If the retrieval system fails to bring in the right documents, the model is essentially reasoning with blind spots. This makes retrieval architecture one of the most important (and often overlooked) parts of the entire system.
The critical metric here is evidence coverage — how comprehensively relevant information makes it into the model’s context. Single-query systems often suffer from low recall. Multi-query expansion directly improves this by increasing both lexical diversity and semantic reach. In many cases, adding just two or three smart variants can meaningfully boost answer quality and consistency.
The Real-World Benefits You Actually Feel
When implemented well, multi-query expansion delivers noticeable improvements. It surfaces more relevant sources, even when they’re worded differently from your question. It makes the system more robust to natural human language variations. It brings greater diversity of perspectives and publishers. And it provides richer, cross-validated evidence, leading to more grounded and trustworthy answers.
Even modest expansion can significantly widen the net without adding much latency. Documents that appear across multiple query versions naturally rise in priority, as they tend to represent more central ideas on the topic.
Where AI Search Is Heading Next
The future of AI search isn’t only about scaling up models. It’s increasingly about building more intelligent retrieval systems.
We’re seeing architectures that combine LLM-powered query rewriting, dense vector search, learned rerankers, and adaptive context compression. The most advanced systems can dynamically decide how much expansion or iteration is needed based on the query type.
Retrieval is no longer treated as a simple preprocessing step. It has become a first-class component in the AI search stack.
The next time an AI search engine gives you slightly different answers to the same question, remember: it may not be randomness at work. It could be the system actively trying to overcome the natural limitations of language through smarter retrieval.
Multi-query expansion is one of those elegant, high-impact techniques that quietly makes AI search more reliable, comprehensive, and useful. It doesn’t try to outsmart the user — it simply helps the machine understand the full breadth of what’s being asked.
As AI search continues to evolve, improvements in retrieval architecture may prove just as important as improvements in the models themselves.
Note:
We have experimented with implementing multi-query expansion inside Poniak Search to improve retrieval coverage. If you’re curious how it behaves in practice, you can try it at poniak.ai.



{kind=link}
{kind=link}