

Multi-query retrieval improves coverage, but broader retrieval also increases noise. In production-grade AI search systems, reranking is the layer that decides which evidence is trustworthy, relevant, and timely enough to reach the model.
The Problem After Retrieval
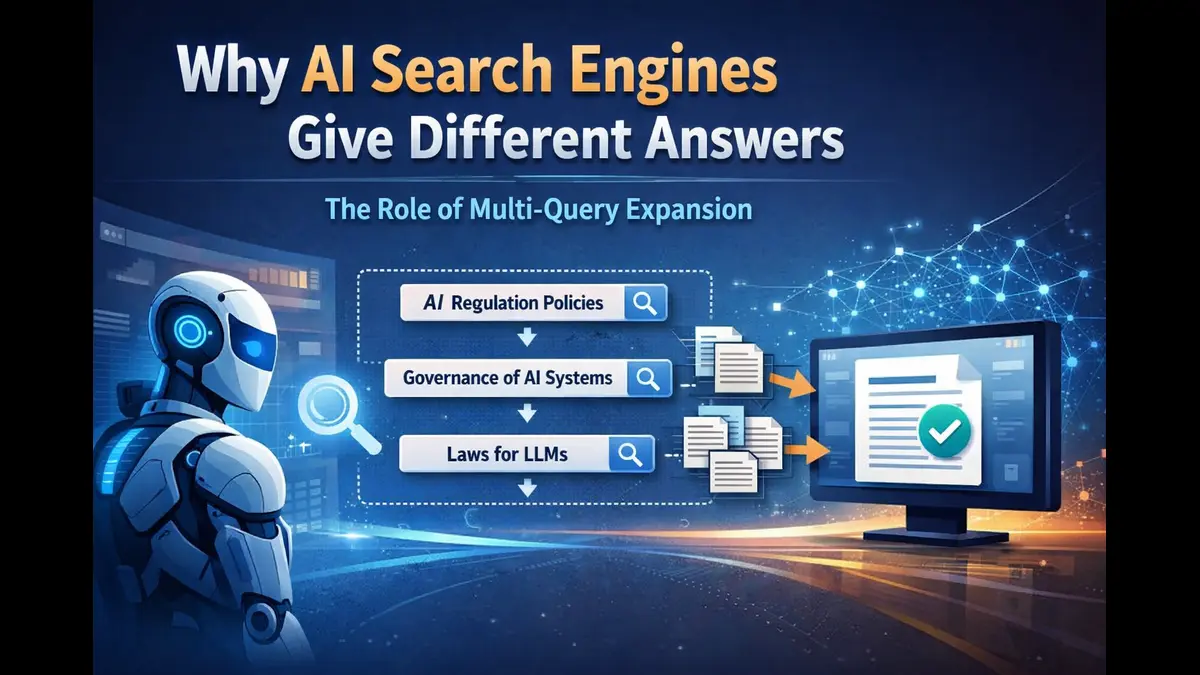
Whenever in a scenario, we ask the same detailed question to an AI search engine twice, and we notice the answers does feel noticeably different each time. One response may emphasize a certain set of facts or sources, while another answer leans on a different mix of evidence. It is easy to assume this comes down to model randomness alone. However, the real difference begins earlier in the pipeline.
Modern AI search systems are built on Retrieval-Augmented Generation, or RAG. The system first retrieves candidate material from the web, internal data, or uploaded documents. It then selects a subset of that material and passes it to the language model, which generates the final answer. Retrieval has improved dramatically in recent years. The harder problem now is not simply finding documents, but deciding which of those documents deserve to shape the response.
That decision happens after retrieval, in the reranking layer.
Multi-query expansion and hybrid search help widen coverage by searching across several phrasings of the same question. That is useful because information on the internet is rarely labeled in the same language the user chooses. But broader retrieval creates an immediate second challenge: once dozens of results are retrieved, the system has to separate strong evidence from weak evidence, central documents from peripheral ones, and timely sources from stale /older ones.
The real difficulty test arises the moment retrieval succeeds.
Why More Results Can Hurt
It often sounds intuitive that more search results should produce better answers. In practice, the opposite is often true.
Language models do not benefit equally from everything placed into context. They have finite token budgets, real latency constraints, and known weaknesses when too much information is packed into a prompt. Important details buried in the middle of a long context can receive less attention. Low-value documents consume space that could have gone to better evidence. Outdated pages, weak sources, or loosely related results dilute the quality of the prompt before generation even begins.
This is where many search systems quietly lose quality. A retriever can do its job well and still hand the model a big messy bundle of evidence. Once that happens, the model is forced to reason over the contradictions, irrelevant details, and uneven source quality. The answer may become vague, over-cautious, or simply less useful than it should have been.
Hence the goal of retrieval is not maximum volume, but – maximum useful signal.
What a Reranker Really Does

A reranker is the quality-control layer between retrieval and generation.
Its job is not to fetch new information. It works on the documents that have already been fetched from the retrieval layer and assign scores to them again using a more precise view of usefulness for the exact query. Search engines and retrieval APIs are optimized for broad candidate generation.
Reranking applies a second, finer level of judgment.
That second pass matters because raw retrieval rank is often too crude for answer generation. A result may be generally related to the topic but still not deserve a place in the model’s final context. Another document may appear lower in the original search results yet contain the most trustworthy or directly relevant evidence.
Reranking fixes this gap. It reorders and filters the best candidate sets so the strongest evidence is more likely to survive into the final prompt.
In real practice, reranking is not one score but a composite decision rule shaped by the query type.
Trust, Freshness, and Relevance
A good reranking layer does not rely on a single signal. It balances at least three: trust, freshness, and relevance.
- Trust measures source authority in context. For a coding question, official documentation and primary technical references should usually carry more weight than generic blogs. For academic queries, research databases and primary papers matter more than general summaries. For product or community-oriented questions, review sites, forums, or discussion platforms may deserve a larger role. Source quality is not universal; it depends on what kind of question is being asked.
- Freshness measures how recent the information is and how much recency should matter. This is crucial because not every query has the same relationship to time. A breaking news question may require material from the last few hours. A product benchmarking query may care about the last few months. A technical explanation of a stable concept may not need recency to dominate at all. Without adaptive freshness scoring, systems either overvalue new material or unfairly penalize older but still authoritative sources.
- Relevance measures how directly a document helps answer the actual question. This goes beyond simple keyword overlap. One especially useful signal is cross-query overlap: if a document appears across multiple expanded variants of the same query, it is often a sign that the document sits near the center of the topic rather than at its edge.
These signals can be combined in simple terms like this:
Final score = weighted trust + weighted freshness + weighted relevance
The formula matters less as mathematical artefact and more as a systems principle: ranking should reflect real usefulness, not merely the order in which documents were retrieved.
Ranking for Intent, Not Just Keywords
The same ranking logic should not be applied blindly to every question.
Consider two queries. One asks about a breaking geopolitical development. The other asks how to fix a React hydration error. The first should heavily reward freshness and credible reporting. The second should prioritize official framework documentation, precise technical guidance, and trustworthy implementation details. A universal ranking formula would treat both tasks too similarly, even though the user’s needs are completely different.
This is why modern AI search systems have to rank for intent, not just for keywords.
A breaking news query should elevate recent reporting from trusted outlets. A coding query should heavily favor official docs and technically precise references. Academic research should prioritize methodological depth and primary sources. Product evaluation may benefit more from user reviews, launch context, or market comparisons.
Once ranking adapts to intent, retrieval stops being a one-size-fits-all mechanism. It becomes a more intelligent evidence selection system.
Why Reranking Changes Final Answer Quality
The language model can only reason over the evidence it receives. That sounds obvious, but it is one of the most important truths in AI search.
If the model receives noisy, weak, or poorly ordered context, even a strong model will struggle to produce a clean answer. If it receives tightly selected, trustworthy, and relevant evidence, the answer becomes clearer and more grounded.
A well-designed reranker improves answer quality in several concrete ways. It pushes high-signal material toward the front of the context. It reduces contradictions caused by stale or peripheral documents. It makes citations more reliable because the surviving sources are better aligned with the user’s actual question. It also lowers the probability of hallucination by giving the model a cleaner evidence base to work from.
In many real systems, improving reranking produces a larger gain in answer quality than simply swapping in a bigger model. The glamorous part of AI search is often generation. The decisive part is often evidence selection.
The Real Job of an AI Search System
The quality of an AI search engine is not determined only by how many documents it can retrieve or how large its language model is. It is determined by how effectively it selects the right evidence under the real constraints of context length, latency, and cost.
Retrieval finds possibilities. Reranking decides the evidence.
As AI search systems mature, the reranking layer is emerging as one of the highest-leverage parts of the pipeline. It is the mechanism that turns broad retrieval into usable context, and usable context into better answers.
We have been experimenting with a custom reranking layer inside Poniak Search that evaluates retrieved documents using trust, freshness, and relevance signals. If you’re curious how it behaves in practice, you can explore it at poniak.ai.


{kind=link}
{kind=link}