
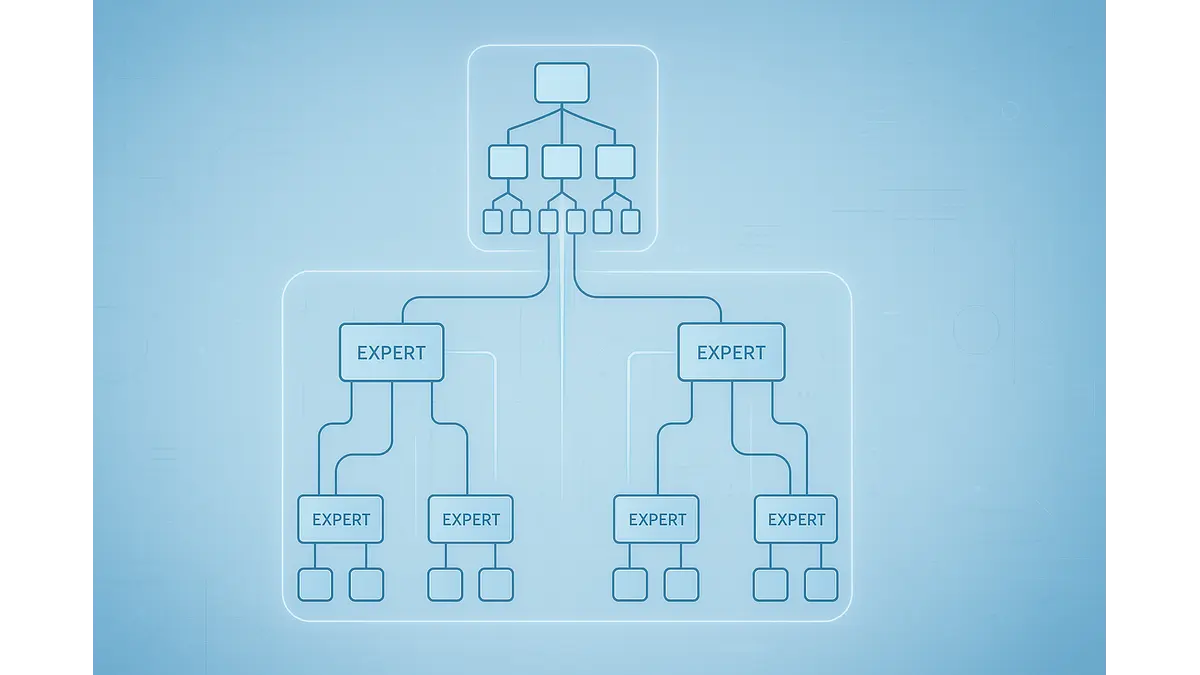
This article introduces a structured curriculum to train Hierarchical Reasoning Models(HRM)–Mixture of Experts(MOE) hybrid systems — combining reasoning depth with scalable specialization. It’s a blueprint for building intelligent, trustworthy systems across domains like finance, education, and defense.
The convergence of hierarchical reasoning models (HRMs) and mixture of experts (MoE) systems represents a transformative approach in artificial intelligence, blending structured problem-solving with scalable computation. HRMs, inspired by the layered cognitive processes of the human brain, excel at breaking down complex tasks into sequential steps, as demonstrated by compact models achieving over 40% accuracy on the Abstraction and Reasoning Corpus (ARC) with just 27 million parameters, surpassing larger pre-trained systems in abstract visual reasoning tasks. MoE architectures, by selectively activating specialized sub-networks, enable massive scaling with reduced computational overhead, as seen in models like Mixtral 8x7B, which rival dense counterparts while activating only a fraction of parameters per input. Here we try to outline a disciplined training pipeline to harmonize these paradigms, addressing challenges like gradient instability and token misrouting through phased learning, domain-specific pretraining, and joint optimization. By progressively escalating task complexity, the framework fosters systems that are accurate, efficient, and interpretable, ready to tackle diverse challenges in fields from education to enterprise analytics.
Introduction
Imagine assembling a team of specialists—each a master in their domain, yet able to collaborate seamlessly to solve intricate problems. This is the vision behind integrating hierarchical reasoning models (HRMs) with mixture of experts (MoE) systems, a synergy that promises to elevate AI’s reasoning capabilities while maintaining computational efficiency. HRMs organize computation in a layered hierarchy, much like how humans approach complex tasks by breaking them into manageable steps. Recent advancements underscore their potential: a compact HRM with interdependent recurrent networks has solved extreme-difficulty Sudoku puzzles and achieved notable results on ARC-AGI, a benchmark for abstract visual reasoning, using just 1,000 training examples. This efficiency stems from its ability to process inputs at multiple levels, with lower layers handling immediate details and higher ones orchestrating strategic plans.
MoE systems complement this by dividing a model into specialized experts, activated selectively through gating mechanisms. This sparsity allows for massive scaling—models with billions of parameters can operate efficiently by engaging only a subset per task, as demonstrated by architectures like Mixtral, which maintain high performance on language and multimodal tasks with minimal active parameters. However, merging these paradigms presents significant challenges. Gradient instability, where updates fail to propagate evenly across layers, can disrupt training, leading to suboptimal convergence. Token misrouting—directing inputs to inappropriate experts—further complicates matters, causing load imbalances that reduce efficiency, as observed in early MoE implementations where a few experts dominated while others idled.
The solution lies in a structured training curriculum, akin to guiding a team through a progressive learning journey. By carefully sequencing tasks and aligning hierarchical decomposition with expert activation, this approach mitigates misalignment and ensures robust convergence. Drawing from established practices in curriculum learning, that have accelerated training and improved generalization in diverse AI tasks, this pipeline builds systems that are not only powerful but also practical for real-world applications, from solving mathematical puzzles to processing multimodal data in enterprise settings.
Pretraining Experts on Domain-Specific Tasks
The cornerstone of an effective MoE system is its experts, each meticulously trained to excel in a specific modality. This initial phase focuses on pretraining these experts independently, ensuring they achieve high specialization—often exceeding 90% accuracy—before integration into the hybrid framework. By targeting distinct domains like symbolic math, natural language, logical inference, and visual processing, experts develop deep fluency in their respective areas, forming a robust foundation for the system.
For mathematical reasoning, datasets like MATH and GSM8K are pivotal. MATH includes 5,000 competition-level problems, spanning algebra, geometry, and calculus, challenging models to solve complex equations with precision. GSM8K, with its 8,500 grade-school word problems, emphasizes multi-step arithmetic embedded in linguistic contexts, training models to extract numerical operations from text. For example, a GSM8K problem might ask, “If a store sells 3 apples for $2, how much for 12 apples?” requiring the model to compute ratios and scale appropriately. Language experts leverage expansive corpora like The Pile, an 825-gigabyte collection of diverse texts from books, web pages, and code, or BookCorpus, which focuses on narrative structures to enhance comprehension of long-form text.
Logical reasoning experts draw on benchmarks like ARC, which presents visual puzzles requiring pattern recognition and rule induction, and StrategyQA, where multi-hop questions demand implicit reasoning to produce yes/no answers from decomposed facts. A StrategyQA example might be, “Can a penguin survive in the Sahara?” requiring steps to evaluate climate, biology, and adaptation. Vision experts utilize datasets like COCO, with 117,000 images for object detection across 80 categories, and DocVQA, which involves extracting information from document scans, blending visual and textual processing for tasks like interpreting invoices or charts.
Training employs supervised fine-tuning to minimize errors on labeled data, ensuring experts master their domains. Contrastive pretraining further refines performance by teaching models to distinguish subtle differences, such as identifying distinct objects in COCO’s (Common Object in Context) crowded scenes or parsing nuanced logical patterns in ARC. This phase results in a suite of highly specialized experts, each primed to contribute to the hybrid system’s overall capability, setting the stage for seamless integration with the HRM.
Training the HRM Decomposition Engine
With experts honed, the focus shifts to developing the HRM’s ability to decompose inputs into structured, sequential sub-tasks, creating a clear blueprint for problem-solving. This phase is akin to teaching a conductor to orchestrate a symphony, ensuring each section plays in harmony. Supervision draws from diverse sources to guide the HRM’s learning. Human-annotated decomposition trees, such as those provided in StrategyQA, break questions into factual steps—for instance, decomposing “Can a dog climb Mount Everest?” into queries about physical capabilities, environmental conditions, and logistical feasibility. Synthetic chains, distilled from larger dense language models, transfer structured reasoning patterns efficiently, leveraging the knowledge of models like GPT-4 to generate step-by-step plans.
Symbolic datasets with traceable intermediate states, such as logic puzzles or graph-based problems, provide additional structure. For example, a logic grid puzzle might include intermediate clues that guide the model toward a solution, allowing optimization through multi-step losses that penalize deviations at each reasoning layer. Intermediate checkpointing further stabilizes training by saving progress at key intervals, preventing loss of learned patterns during long sequences. The curriculum begins with shallow decompositions—1 to 2 layers—for simple tasks like basic arithmetic or single-object recognition in images. As training advances, it scales to deeper hierarchies, enabling the HRM to handle complex inputs, such as multi-step logic puzzles or multimodal queries combining text and visuals.
This gradual escalation ensures the HRM produces coherent, explainable outputs, such as JSON trees for structured plans or logic clauses for inferences. These outputs are critical for guiding MoE routing in later phases and enhancing system transparency, allowing users to follow the AI’s reasoning process. The result is a decomposition engine that not only breaks down problems effectively but also sets a clear path for integrating specialized experts, ensuring the system operates as a cohesive whole.
Joint Optimization with MoE Routing
The integration of MoE experts with HRM sub-task levels marks a critical juncture, where the system learns to route inputs to the most appropriate specialists while maintaining hierarchical coherence. This phase is like choreographing a dance, where each move must align with the rhythm of the music. Gating functions, such as softmax for probabilistic selection or top-k for sparse activation, are trained to direct inputs efficiently. Load-balancing losses, like auxiliary entropy or Sinkhorn divergence, prevent imbalances where a few experts dominate, ensuring all specialists contribute meaningfully. Without such measures, training risks collapse, as observed in early MoE systems where underutilized experts led to inefficiencies.
Reinforcement signals from successful expert outputs refine routing decisions, rewarding gates that select the right specialists for each sub-task. Straight-through estimators address the challenge of discrete gate decisions, allowing gradients to flow during backpropagation despite non-differentiable choices. Joint gradient updates harmonize HRM and MoE objectives, aligning hierarchical decomposition with expert activation. For example, in a multimodal task combining text and images, the HRM might decompose the query into text parsing and visual analysis, with gates routing each component to the appropriate language or vision expert. This phase yields a system where routing precision complements reasoning depth, achieving high accuracy on benchmarks like GSM8K and StrategyQA by ensuring inputs reach the most suitable specialists.
Learning Strategy
The success of this pipeline hinges on curriculum learning, which introduces complexity gradually to prevent training collapse. This approach mirrors human education: mastering basic skills before tackling advanced challenges accelerates learning and improves generalization. The curriculum unfolds in stages, starting with single-hop reasoning tasks involving few experts, such as solving simple arithmetic problems with a math specialist. It progresses to shallow decompositions with predefined expert mappings, like breaking a logic puzzle into two steps with known expert assignments. Finally, it scales to full hierarchical plans with dynamic gating, handling multimodal tasks that combine text, images, and logic.
Task progression spans domains: from arithmetic (e.g., GSM8K’s word problems) to grid-based reasoning (ARC’s visual patterns) and multimodal forecasting, such as predicting outcomes from text and charts. Progress is tracked through metrics like solve rates, which measure accuracy; reasoning depth, which evaluates layer utilization; and routing entropy, which assesses gate balance. This deliberate escalation ensures stable convergence, enabling the system to handle increasingly complex tasks without sacrificing efficiency or accuracy.
Intermediate Supervision and Hybrid Labels
To ensure clarity in sub-task outputs, intermediate supervision plays a vital role. Symbolic targets, such as annotated Sudoku steps or causal graph edges, guide the HRM to produce precise intermediates. Chain-of-thought (CoT) chains, derived from human annotations or synthetic distillation, serve as pseudo-labels, providing step-by-step reasoning paths. For instance, a CoT chain for a math problem might outline each arithmetic operation explicitly, helping the HRM learn structured outputs.
Output formats like JSON trees for hierarchical plans or logic clauses for inferences enhance auditability, allowing stakeholders to inspect the system’s reasoning. Supervision blends direct loss minimization for labeled intermediates, policy imitation from expert demonstrations, and reinforcement rewards for successful completions. This hybrid approach ensures sub-tasks align with expert capabilities while maintaining transparency, fostering trust in the system’s decisions and enabling refinements in critical applications like medical diagnostics or financial modeling.
Evaluation Metrics and Benchmarks
Rigorous evaluation validates the curriculum’s effectiveness across multiple dimensions. Reasoning quality is assessed using benchmarks like GSM8K, StrategyQA, BigBench’s reasoning suite, and MATH, targeting accuracies above 85%. GSM8K tests multi-step arithmetic in word problems, while StrategyQA evaluates implicit reasoning through multi-hop questions. BigBench and MATH challenge advanced inference across diverse domains, ensuring the system handles complex tasks robustly.
Routing metrics focus on efficiency and balance: entropy measures activation diversity, aiming for high spread to utilize all experts; the Gini index, targeting below 0.2, ensures even token-to-expert distribution; and overlap metrics track expert sharing across tasks. Efficiency is evaluated through FLOPs per token versus accuracy curves, comparing computational cost to performance, and latency benchmarks assess asynchronous routing speed. Robustness tests include ablations—removing experts or shortening reasoning plans—and stress tests with adversarial inputs or missing steps, ensuring the system remains resilient under challenging conditions.
Scaling and Deployment Implications
The modular nature of this curriculum facilitates scaling and deployment, making it practical for real-world applications. Experts can be trained in parallel across GPUs, reducing time and resource demands. Composable HRM blocks adapt to specific domains, such as financial risk modeling or medical diagnostic trees, allowing tailored solutions without redesigning the entire system. MoE’s conditional activation supports this scalability, enabling models with billions of parameters to operate efficiently by engaging only necessary experts, as seen in deployments where inference costs are significantly lower than dense models.
Future directions include transfer learning to adapt experts across domains, such as applying a math expert to financial forecasting, and lifelong learning to update experts continuously with new data. These capabilities position HRM-MoE hybrids as compute-efficient, interpretable agents, ideal for enterprise applications where reliability and transparency are paramount, from optimizing supply chains to enhancing educational tools.
Training HRM-MoE systems is a journey of disciplined progression, transforming complex challenges into a structured learning path. By combining expert specialization, curriculum-driven escalation, and robust supervision, this framework builds AI systems that excel in reasoning while remaining scalable and transparent. The result is a roadmap that not only engineers powerful AI but also ensures it meets the demands of real-world applications, paving the way for a new era of intelligent, trustworthy systems.
Discover more from Poniak Times
Subscribe to get the latest posts sent to your email.




{kind=link}
{kind=link}