
Retrieval-Augmented Generation (RAG) is redefining how AI systems think and respond by combining live data retrieval with generative intelligence. It bridges the gap between static large language models and dynamic real-world information, creating faster, more factual, and context-aware AI applications across industries like finance, healthcare, and education.
Retrieval-augmented generation (RAG), one of the most advanced Artificial Intelligence frameworks, has created a huge opportunity to revolutionize applications across multiple businesses, combining the effectiveness of traditional information retrieval systems with generative AI.
What Is Retrieval-Augmented Generation (RAG)?
The concept of RAG first appeared through Meta AI (previously known as Facebook) in the year 2020. It explained RAG as a way of linking LLMs with any internal or external knowledge source to enhance the quality of response generated by LLMs and mitigate some of the limitations of the LLMs.
The RAG framework works on two processes -Retrieval and Generation of the data:
- Retrieval:
It accesses external data sources to fetch relevant information based on the user’s query.
- Generation:
The LLM then generates more up-to-date and accurate information based on the original prompt given by the user. The response generated by the LLM is now more informed and personalized.
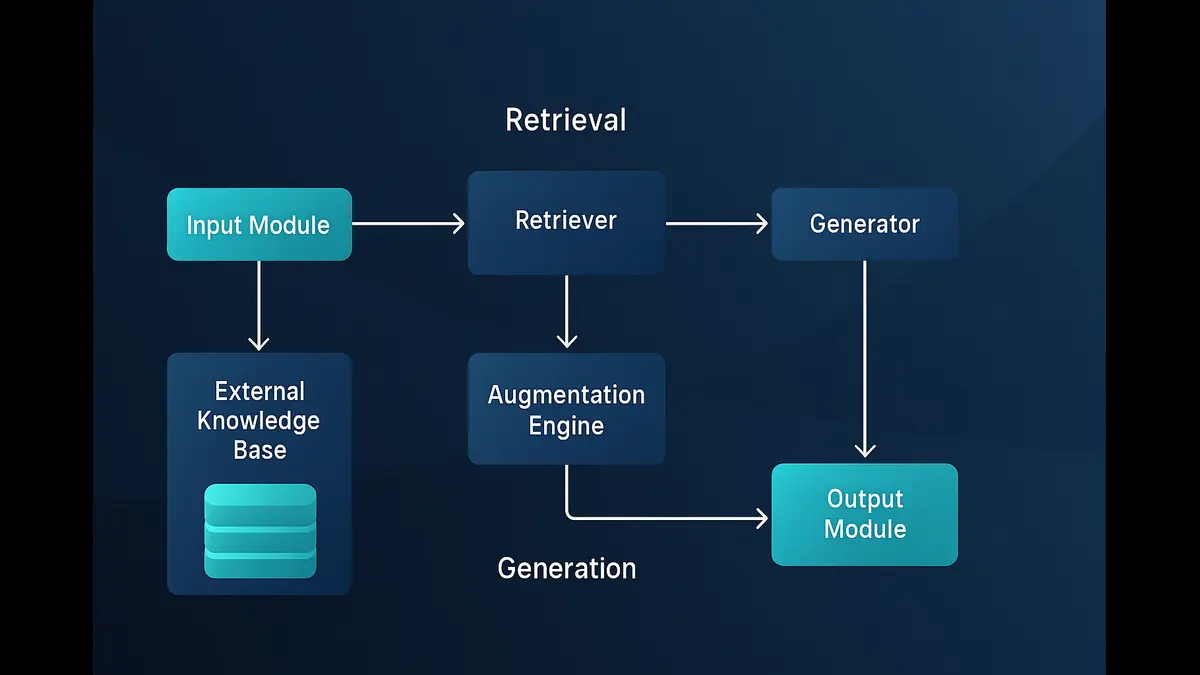
How RAG Works — The Dual Engine of Retrieval and Generation
RAG comprises several key components that collaborate and enhance the capabilities of LLMs by integrating them with an external knowledge base.
- Input Module:
It is the first step towards retrieval and generation processes. In this module user queries and prompts are captured.
- Retriever:
This module fetches the relevant information from external knowledge bases and sources. The module can use Sparse retrievers, Dense retrievers, or Domain-specific retrievers based on which type of data retrieval is required.
- Augmentation Engine:
This component processes the retrieved data to prepare it for the generation phase based on data relevance and adding contextual information to the data.
- Generator:
This module creates the final output based on the input and the augmented data.
- Output Module:
It provides the output to the users and ensures it meets the user’s expectations.
Why RAG Matters — Overcoming LLM Limitations
Traditional LLMS has several limitations that are effectively mitigated in the RAG Framework:
- Reductions of Hallicuniations:
The LLMs generate responses based on the training data, however, if the data that was used to train the model is incomplete, biased, or not relevant to the user’s query the response they produce can be inaccurate, commonly known as Hallucinations. By integrating LLMs with real-time data from trusted sources, RAG ensures that the response generated is factual and reliable.
- Access to real-time and trusted sources:
Traditional LLMs are trained on static data that may not be up-to-date. RAG allows LLMs to access the latest data sources and enhance their knowledge of dynamic information.
- Contextual Relevance:
RAG improves the contextual understanding of users’ queries by leveraging external sources of data and provides an accurate response aligned with users’ queries and expectations.
- Trust and Transparency:
RAG systems can provide users with insights into where the information comes from, fostering greater trust in AI-generated content. Users can verify the accuracy of responses based on the sources utilized during retrieval.
Real-World Applications Across Industries
- Healthcare:
RAG provides evidence-based answers to Healthcare professionals by retrieving data from extensive medical literature related to the latest medical research, treatment guidelines, or drug interactions to support their clinical decisions.
- Finance:
The financial sector has a wide range of applications in RAG, as it enables users to get real-time insights by fetching data from market feeds and financial reports on stock performance, market indicators, and trends thus improving their decision-making processes.
- Education:
RAG enables users to get personalized learning experiences by providing dynamic educational content such as generating customized quizzes and explanations based on the learner’s requirement and learning progress.
- Customer Support:
RAG plays a significant role in improving customer satisfaction by facilitating customer support services where chatbots can retrieve relevant product information and customer history to provide personalized responses,
- Legal Sector:
To perform legal research with a large amount of data is practically difficult and time-consuming, RAG enables users to draft case summaries and research precedent cases and clauses for preparing legal documents.
- Content Creation:
RAG helps Journalists and content creators get accurate data, facts, and numbers so that they can create informed and engaging content.
Challenges and Limitations
There are challenges involved in RAG applications like integrating with diverse and various external databases can be complex and may require a lot of technical effort and standardization. Another challenge can delay retrieval, especially in the case of real-time data retrieval, this can impact the overall performance of the RAG applications.
RAG is transforming various industries by providing accurate and creative content by utilizing LLM capabilities and external data retrieval overcoming the limitations of traditional data retrieval mechanisms.RAG is further evolving and expanding its horizon across industries, and building trust in AI-generated content in real-world scenarios. It can further expand its capabilities in critical areas such as policy-making and defense.
The Road Towards Smarter, Context-Persistent AI
As artificial intelligence advances beyond static reasoning into dynamic, memory-aware systems, Retrieval-Augmented Generation (RAG) stands as the connective tissue linking today’s data-driven models with tomorrow’s autonomous intelligence. Future frameworks like agentic AI and JEPA-based architectures are being designed to reason continuously, remember context over long horizons, and align actions with goals rather than single prompts.
RAG provides the factual spine these systems rely on—ensuring every act of reasoning is grounded in verifiable, transparent information. When combined with self-updating world models and reflexive feedback loops, it moves AI closer to true contextual persistence: agents that learn, recall, and adapt without losing fidelity to truth.
The next evolution of RAG will likely merge retrieval, reasoning, and reflection, enabling AI systems not only to generate informed responses but to justify them, audit their sources, and learn from their own outputs. This synthesis marks the beginning of a more responsible and self-aware era of artificial intelligence—an age where knowledge isn’t just generated, but genuinely understood.
Discover more from Poniak Times
Subscribe to get the latest posts sent to your email.







{kind=link}
{kind=link}