
Modern AI products cannot rely on one large language model for every task. This article explains how model routing helps production AI systems choose the right model, tool, retrieval pipeline, or workflow based on cost, speed, accuracy, and reliability.
The first generation of AI products was built around a simple assumption: bigger models produce better products.
That assumption is now breaking down.
In production, the best AI system is not always the one that calls the most powerful model for every task. It is the one that knows when to use a frontier model, when to use a smaller model, when to retrieve documents, when to call an API, and when to avoid an LLM entirely.
A legal summary, a customer-support ticket, a coding task, a database lookup, a calculation, and an agent workflow are not the same problem. They should not be handled by the same intelligence layer.
This is why model routing is becoming a core architectural pattern in modern AI systems.
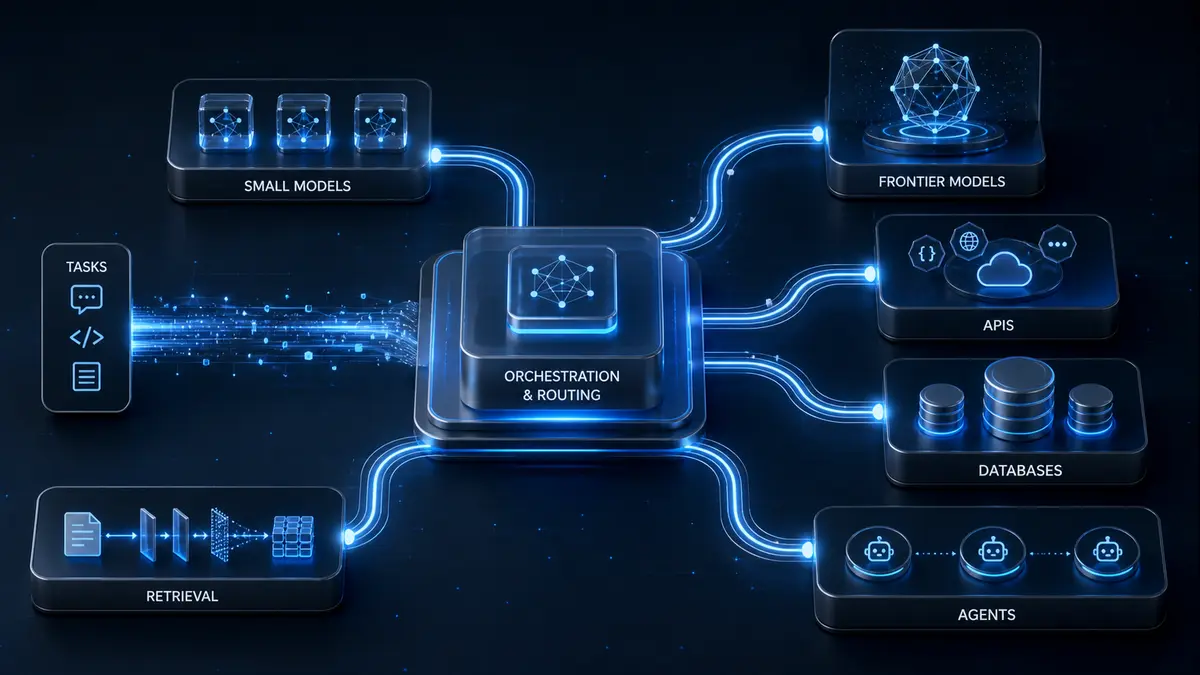
Model routing is the process of directing each query, request, or task to the most suitable model, tool, or workflow. Instead of sending everything to one large model, a routing layer decides whether the work should go to a lightweight model, a frontier model, a specialized model, a retrieval pipeline, a deterministic tool, or a multi-step agentic workflow.
The idea is simple but powerful: use the right intelligence for the right task.
Why the “One Model for Everything” Approach Breaks Down
A single LLM may look impressive in a demo, but real-world AI usage is messy. Users and businesses do not ask only one type of question. They ask for summaries, calculations, comparisons, coding help, policy explanations, report generation, customer support, research assistance, workflow execution, and document analysis.
Each of these tasks has different requirements.
A complex legal or financial analysis may need retrieval, citations, and a strong reasoning model. A support-ticket classification task may only need a smaller classification model. A basic arithmetic query should go to a calculator. A weather query should go to a weather API. A database question should be answered by querying the database, not by asking a language model to guess.
No single model is equally good, equally fast, and equally economical across all these scenarios.
Performance varies widely across tasks. Frontier models from OpenAI, Anthropic, Google, xAI, and others may excel at reasoning, coding, and synthesis, but they are not always the most efficient choice for simple extraction, classification, formatting, or tool-based tasks. Smaller or specialized models can be faster and cheaper for narrow workflows, especially when deep reasoning is not required.
The bigger issue is economics. Production AI products operate at scale. A customer support system, enterprise assistant, coding copilot, research tool, workflow agent, or internal knowledge platform may process thousands or millions of requests. If every request is sent to the most expensive model, costs can rise quickly.
The system may still work technically, but the business model becomes weak.
Latency also matters. Users expect AI systems to respond quickly. If a simple request is routed through a heavy model unnecessarily, the product becomes slower without becoming meaningfully better. In production AI, unnecessary intelligence can become a user-experience problem.
There is also reliability risk. A monolithic model setup creates a single point of failure. If the model provider has an outage, changes model behavior, hits a rate limit, or introduces unexpected performance changes, the entire product may suffer. A routed system can provide fallback options, alternate providers, and more resilient execution paths.
Not Every Task Needs an LLM
One of the biggest mistakes in early AI architecture is using LLMs for tasks that do not require language generation.
A user asking for a currency conversion does not need a frontier model. A user asking for current weather needs a weather API. A user asking for a mathematical calculation needs a calculator. A user asking for a customer record needs a database query. A user asking for current stock data needs a reliable market data source.
In these cases, the LLM may still be useful for formatting the answer, explaining the output, or turning structured data into natural language. But it should not be the source of truth.
This is an important distinction. Model routing should often be understood as task routing or tool routing.
A mature AI system does not ask, “Which LLM should answer this?” as the first question. It asks, “What is the correct path for this request?”
Sometimes the right path is a small model. Sometimes it is a large model. Sometimes it is retrieval. Sometimes it is a calculator. Sometimes it is an API call. Sometimes it is a multi-step agent that uses several tools before producing the final answer.
That is why model routing is not only about choosing between Model A and Model B. It is about choosing the right execution path.
What Model Routing Actually Looks Like
A model router sits between the user request and the rest of the AI system. Its job is to inspect the request, understand the task, and decide where it should go.
The simplest form is static routing. In this setup, rules are predefined. If the user selects “coding mode,” the request goes to a coding-optimized model. If the user selects “writing mode,” it goes to a model better suited for drafting and editing. If the user selects “data analysis,” the system may prioritize tools, tables, and calculation workflows.
Static routing is easy to understand and useful for early products. It gives teams control, reduces complexity, and works well when user workflows are predictable.
Dynamic routing is more advanced. Here, the system analyzes each request on the fly. It may look at query length, intent, complexity, subject matter, user tier, available context, required freshness, and the need for external tools. Then it chooses the best path.
There are several common approaches.
Rule-based routing uses simple heuristics. For example, a query containing “calculate” may go to a calculator. A request asking for database information may trigger a database lookup. A long analytical prompt may be routed to a stronger reasoning model.
Semantic routing uses embeddings. The system compares the user’s request with previous examples and routes it to the model or workflow that performed best on similar requests.
Classifier-based routing uses a small model to predict intent or complexity. The classifier may decide whether the request is simple, complex, factual, creative, coding-related, compliance-sensitive, or tool-driven.
Cascade routing starts with a cheaper or faster model. If the system detects low confidence, incomplete reasoning, or insufficient answer quality, it escalates to a stronger model. This approach can preserve quality while reducing unnecessary premium-model usage.
Advanced learned routers try to predict which model or workflow will perform best before generating the full response. These systems may use preference data, historical performance, latency constraints, and cost targets to make better routing decisions.
In simpler words, a good router acts like a disciplined operations manager. It does not send every task to the most senior expert. It sends each task to the right person, tool, or team.
Routing Becomes More Important in RAG Systems
Model routing becomes even more important when retrieval-augmented generation, or RAG, is involved.
A basic RAG system retrieves relevant documents and sends them to an LLM for answer generation. But different models handle retrieved context differently. One model may be better at extracting precise facts. Another may be better at synthesizing long documents. Another may be better at refusing unsupported claims. Another may perform better on technical documentation or legal language.
This means the best model is not determined only by the user’s request. It also depends on the retrieved context.
For any AI system that uses retrieval, this is a major insight. The system should not only ask, “What did the user request?” It should also ask, “What kind of evidence did we retrieve, and which model is best suited to reason over this evidence?”
A financial filing, a medical policy document, a software manual, a legal contract, and a customer support ticket may each require a different reasoning style. Routing allows the system to adapt instead of forcing every document and every task through the same model.
This is especially important for enterprise AI systems. Internal documents are often messy, long, inconsistent, and domain-specific. A single LLM may not always handle every type of document with the same reliability. Routing creates room for specialization.
Model Routing in AI Agents
AI agents make routing even more important.
An agent is not simply answering a question. It may be planning steps, calling APIs, searching documents, writing code, updating records, generating reports, or triggering workflows. In this environment, routing becomes the decision layer that determines what happens next.
For example, a business automation agent may receive a request such as:
“Check pending invoices, identify overdue clients, draft reminder emails, and update the CRM.”
This should not be handled as one giant LLM prompt. A better system would route the request across multiple steps. It may query the invoice database, classify overdue accounts, call the CRM API, generate email drafts using a language model, and ask for human approval before sending anything.
In this case, the intelligence is not only in the LLM. It is in the orchestration.
The same applies to coding agents. A coding agent may need to inspect files, search documentation, run tests, explain errors, modify code, and generate a pull request. Some steps require language generation. Others require deterministic tools. Some require a strong reasoning model. Others can be handled by smaller models or direct programmatic checks.
Without routing, agents become expensive, slow, and unreliable. With routing, they become more modular, measurable, and production-ready.
The Business Case: Cost, Speed, and Quality
The strongest argument for model routing is practical.
Routing can reduce LLM costs meaningfully while preserving comparable quality on selected workloads. But the exact savings depend on traffic mix, model prices, router accuracy, fallback design, and how often the system escalates to stronger models.
A product with many simple requests may save significantly through routing. A product with mostly complex research or reasoning tasks may save less. A poor router may send difficult tasks to weak models, harming quality. An overly cautious router may escalate too often, reducing cost benefits.
This is why model routing should not be treated as a magic switch. It is an optimization system.
The best approach is usually gradual. Start with simple rules. Measure performance. Add semantic classification. Introduce escalation. Track cost, latency, user satisfaction, and answer quality.
Routing also supports better user segmentation. A free-tier user may receive fast, efficient responses from smaller models for basic tasks. A premium user may receive deeper reasoning, longer context handling, or more expensive model calls. Enterprise users may require compliance-aware routing, private model options, audit logs, and provider redundancy.
In this way, routing becomes not just a technical design choice but a pricing and product strategy.
The Trade-Offs of Model Routing
Model routing also introduces complexity.
The router itself must be maintained. New models appear frequently. Pricing changes. Context windows expand. Providers update their systems. A routing strategy that worked six months ago may become outdated.
There is also debugging complexity. If a user receives a poor answer, the team must investigate not only the model output but also the routing decision. Did the router classify the task correctly? Was the right model selected? Did retrieval work properly? Was escalation needed? Did a tool fail? Was the wrong context passed?
Latency can also increase if routing is implemented poorly. If the system performs too many classification steps before answering, the user experience may suffer. A good router must be lightweight, fast, and measurable.
This is why observability is essential. Teams should log routing decisions, selected models, tool calls, fallback rates, cost per request, latency, confidence scores, and user feedback. Without monitoring, routing becomes guesswork.
The goal is not to create a complicated system for its own sake. The goal is to create a system that is cheaper, faster, more reliable, and easier to improve over time.
Why Enterprises Are Moving Toward Routing
The rise of model routing reflects a larger market reality. Enterprises do not want to depend on one model provider for every task. They want flexibility, cost control, compliance options, provider redundancy, and workload-specific performance.
A bank may need one workflow for customer support, another for internal policy search, another for software development, and another for risk analysis. A hospital may need routing between document retrieval, structured medical data, scheduling systems, and carefully controlled summarization. A manufacturing company may need AI systems that connect maintenance logs, ERP systems, technical manuals, and operational dashboards.
These are not single-model problems. They are orchestration problems.
For startups too, routing can become a competitive advantage. A startup that intelligently combines tools, small models, large models, retrieval, and fallback systems can often deliver better unit economics than a startup that simply sends every request to one premium model.
In the early days of AI products, a wrapper could impress users. In the next phase, architecture will matter more.
The Future of AI Systems Is Orchestration
The next generation of AI systems will not be defined only by access to the strongest model. It will be defined by orchestration.
Modern AI products need to understand user intent, retrieve the right information, evaluate source quality, call tools when required, select the right model, escalate when needed, and generate reliable outputs. Model routing is one layer in this larger architecture.
This direction also connects with the broader movement toward agentic systems. As AI products become more action-oriented, they will need to decide not just what to say, but what to do next. Should the system search, calculate, summarize, classify, retrieve, ask for clarification, call an API, or use a stronger model?
Routing is the decision layer behind those choices.
In that sense, model routing is not just a cost-saving feature. It is part of the intelligence of the system itself.
One LLM cannot reliably answer every query because user needs are too diverse, economics are too demanding, and model capabilities are too varied.
A serious AI system must know when to use a small model, when to use a frontier model, when to retrieve documents, when to call a tool, when to use deterministic computation, and when to escalate. That decision-making layer is what model routing provides.
For builders, the lesson is clear. Do not build AI products as single-model wrappers. Build them as intelligent systems. Start with simple routing rules, measure everything, and gradually improve the router as usage data grows.
For serious AI products, routing is moving from optional optimization to core infrastructure. The future belongs not only to products with powerful models, but to products that know precisely when and how to use them.


{kind=link}
{kind=link}