
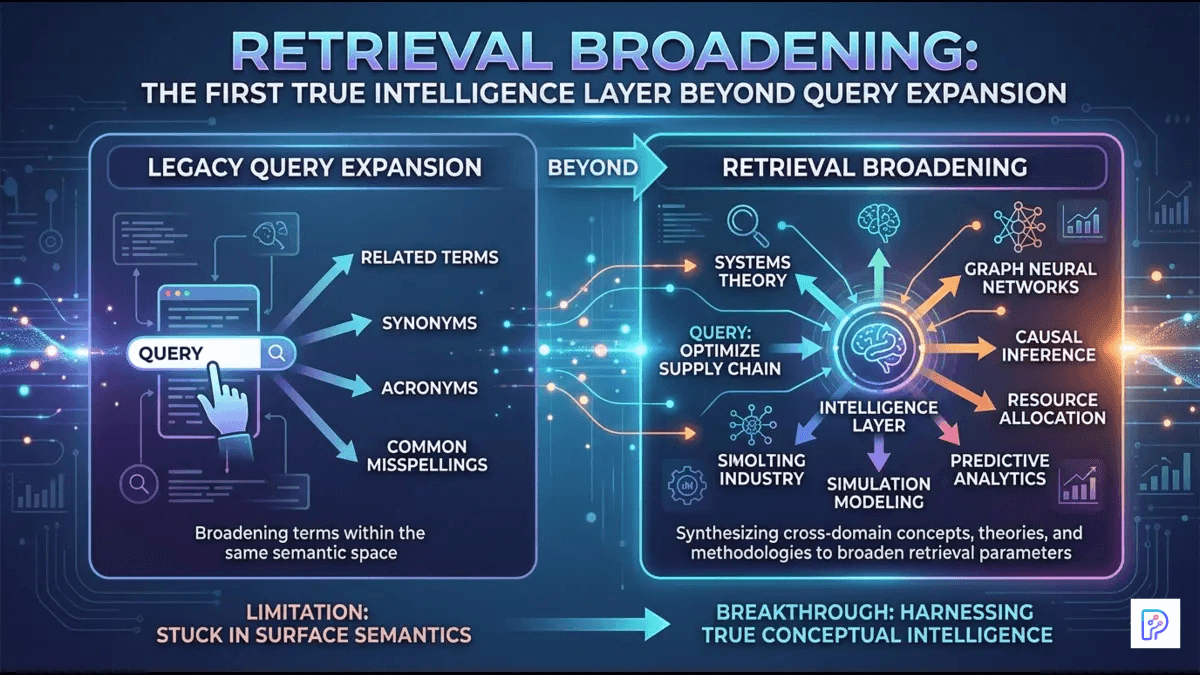
Query expansion improved recall, but retrieval broadening is introducing a deeper intelligence layer into modern AI search systems by dynamically expanding relevance during retrieval itself.
Most users assume that a compelling AI-generated answer is shaped primarily by the language model writing the final response. In reality, the true quality is often determined much earlier – deep inside the retrieval stack, where the system quietly decides which pieces of information even deserve to reach the generator at all.
Query expansion marked an important early improvement by enriching the original user input with synonyms, related terms, and alternative phrasings. Retrieval broadening represents a more profound shift. It moves intelligence from mere input preprocessing into the heart of the retrieval process itself, dynamically expanding the scope of what qualifies as relevant. This hidden layer is increasingly setting the performance ceiling for modern search and generative AI systems.
The Persistent Limitations of Traditional Keyword-Based Retrieval
For years, information retrieval systems relied almost exclusively on exact or near-exact term matching. A seemingly straightforward query such as “bike chain repair” would return documents containing those precise words while frequently overlooking equally valuable content that discussed “bicycle drivetrain maintenance,” “rear derailleur adjustment,” or “chain wear indicators.” This vocabulary mismatch – the gap between casual user language and formal documentation – created chronic blind spots in search results.
Incremental advances like relevance feedback (learning from user clicks or ratings) and vector space models helped improve ranking. Yet these techniques still operated within a fundamentally lexical or statistical framework. Systems excelled at string matching and basic similarity scoring but struggled to capture deeper conceptual relationships. The result was often incomplete coverage: relevant documents remained buried or entirely invisible simply because they used different terminology.
How Query Expansion Emerged as a Practical Breakthrough
Query expansion addressed this vocabulary gap head-on. Rather than depending solely on the user’s original phrasing, the system automatically augments the query with synonyms, semantically related terms, or fully rephrased variants. Approaches range from rule-based synonym dictionaries to pseudo-relevance feedback – where the system analyzes the top initial results to extract promising additional keywords – and LLM-powered rewriting techniques.
In Retrieval-Augmented Generation (RAG) pipelines, this step proved especially valuable. By casting a wider net early in the process, query expansion supplies the downstream language model with richer, more diverse context. This helps mitigate hallucinations and improves the coherence of generated answers. A notable variant is HyDE (Hypothetical Document Embeddings), in which an LLM first generates a synthetic “ideal” answer to the query; the embedding of that hypothetical document then guides retrieval toward more semantically aligned real documents.
Everyday users benefit without realizing the mechanics: vague or awkwardly phrased questions suddenly produce more useful outcomes. For developers, query expansion offers a relatively lightweight win – it boosts recall metrics such as recall@K with manageable added complexity.
The Plateau: Why Query Expansion Alone Is No Longer Enough
Despite its successes, query expansion remains largely a preprocessing technique. It enhances the input but does not fundamentally alter how relevance is judged once candidate documents are retrieved. Aggressive expansion can introduce noise, lowering precision. In complex, multi-hop questions or extended conversational contexts, it often fails to bridge disparate pieces of information scattered across multiple sources or dialogue turns.
Many production systems reach a clear performance plateau at this stage. They grow more adept at guessing related words, yet they still lack the deeper interpretive judgment needed for nuanced or open-ended informational needs. This limitation creates an opportunity – and a necessity – for the next evolutionary step in retrieval architecture.
Retrieval Broadening: The Engineering Mechanics of a Smarter Layer
Retrieval broadening shifts intelligence directly into the retrieval phase. Instead of simply inflating the query upfront, it intelligently widens the scope of relevance through multi-stage, iterative, or post-retrieval processes. The system begins to reason about the user’s underlying informational need and surfaces conceptually connected content even when surface phrasing diverges significantly.
In engineering terms, this involves several interconnected techniques. Candidate set expansion starts with an initial broad retrieval pass – often hybrid – and then grows the pool by mining for semantically adjacent material. Semantic adjacency mining uses embeddings or graph-based methods to identify documents that share latent themes, entities, or implications rather than exact lexical overlap.
Iterative retrieval loops take this further: the system retrieves an initial set, analyzes gaps or missing angles through lightweight reasoning, then issues refined follow-up queries. Post-retrieval entity chaining extracts key entities or concepts from early results and uses them to pull additional supporting documents, creating richer narrative threads.
These mechanisms allow the pipeline to adapt dynamically. A complex research query might trigger multiple broadening passes, gradually building a web of interconnected evidence rather than a flat list of matches. The result is retrieval that feels less like keyword hunting and more like exploratory reasoning.

Why Retrieval Broadening Qualifies as the First True Intelligence Layer
Earlier stages – basic indexing, dense vector embeddings, and even query expansion – were primarily sophisticated forms of pattern matching at scale. Retrieval broadening crosses an important threshold. The retrieval system is no longer merely searching for lexical neighbors of a query; it is beginning to infer the informational neighborhood of the user’s intent.
This inference introduces adaptive judgment: modeling what the user is truly trying to understand, dynamically linking concepts across sources, and balancing breadth (to avoid missing critical context) with precision (to prevent noise). It enables systems to move beyond retrieving isolated facts toward assembling grounded, interconnected insights. In short, retrieval begins to exhibit reasoning-like behavior – the first genuine layer of intelligence after mechanical expansion.
Production Impact: How Leading Systems Are Already Applying It
Real-world implementations illustrate the power of this approach. Perplexity AI’s Deep Research mode operates as an agentic, multi-pass retrieval loop. For complex queries, it performs dozens of iterative searches, reads and reasons over hundreds of sources, refines its research plan on the fly, and aggregates evidence through multiple reasoning steps before synthesizing a comprehensive report. This goes well beyond single-pass expansion, delivering depth through continuous broadening and source reconciliation.
Microsoft’s Azure AI Search demonstrates another mature pattern. It combines BM25 keyword retrieval with vector search in a hybrid query, merges results using Reciprocal Rank Fusion (RRF), and then applies a secondary semantic ranker (powered by deep learning models adapted from Bing) to rescore candidates. This hybrid + semantic reranking workflow consistently improves relevance for generative applications, providing more reliable grounding while controlling latency in enterprise environments.
These architectures show how retrieval broadening powers more trustworthy knowledge assistants, internal enterprise search tools, and advanced research systems. Users receive responses that connect ideas meaningfully rather than offering fragmented or superficial lists. Builders achieve measurable gains in answer faithfulness without depending exclusively on ever-larger language models.
The Necessary Trade-offs and Limitations
Retrieval broadening is not a frictionless upgrade. Each additional retrieval pass, reranking layer, or contextual fusion step increases inference latency, orchestration complexity, and computational cost. Poorly tuned broadening risks flooding the generation stage with semantically adjacent yet ultimately decision-irrelevant material, raising token consumption and potentially diluting focus.
The real engineering challenge is broadening with discipline – implementing intelligent filters, adaptive thresholds, and efficient fusion strategies that preserve precision while expanding coverage. As these systems scale, robust evaluation metrics that assess not only recall and precision but also answer usefulness, faithfulness, and coherence become indispensable. Organizations must carefully weigh these trade-offs against the quality improvements they unlock.
The Strategic Edge in the Years Ahead
In the next phase of AI search and generative systems, competitive advantage will not belong solely to the largest or most capable language model. It will increasingly belong to those who master the retrieval layer intelligent enough to know exactly what the model should read – and why – before it ever begins to speak.
In modern AI systems, the model may deliver the words – but retrieval increasingly decides whether those words deserve trust.
Retrieval broadening is that critical intelligence layer. By evolving beyond query expansion into thoughtful, adaptive information selection, it is quietly redefining the boundaries of what reliable, context-aware AI can achieve. For both builders and users, focusing attention and investment here may prove one of the highest-leverage decisions in the coming years.
Discover more from Poniak Times
Subscribe to get the latest posts sent to your email.






{kind=link}
{kind=link}