
This article delves into the potential of combining Hierarchical Reasoning Models (HRMs) and Mixture of Experts (MoE) to create AI systems that excel in structured reasoning and scalable efficiency. It examines their architectural foundations, integration possibilities, technical hurdles, and transformative applications in fields like finance, healthcare, and defense, charting a course for advanced AI innovation.
The rapid rise of artificial intelligence (AI) has ushered in an era of unprecedented capabilities, with large language models (LLMs) achieving remarkable feats in text generation, task execution, and emergent logical reasoning. Models with billions or even trillions of parameters can craft fluent narratives, synthesize code, and tackle professional-grade queries. Yet, beneath this cover of sophistication lies a critical limitation: the ability to perform robust, multi-step reasoning. When confronted with tasks requiring the decomposition of complex problems, sustained contextual awareness across multiple decision points, or integration of multimodal data—such as text, numerical tables, and images—these models often falter, producing inconsistent outputs, hallucinated facts, or shallow logical chains. This shortfall constrains AI’s reliability in high-stakes domains like Finance, Defense, Supply chain management, Medical diagnostics, and Legal analysis, where precision and traceability are non-negotiable.
Simply scaling model size offers diminishing returns, burdened by escalating computational costs, latency, and energy demands. Instead, two architectural paradigms have emerged as promising solutions, each addressing distinct facets of this challenge. Hierarchical Reasoning Models (HRMs) introduce depth by structuring reasoning into layered, sequential processes that mirror human problem-solving, breaking complex tasks into manageable sub-tasks with explicit intermediate steps. Mixture of Experts (MoE) architectures, by contrast, enable efficient breadth by distributing expertise across specialized sub-networks, activated selectively to minimize resource use. Individually, these approaches have demonstrated significant advantages: HRMs show that structured reasoning can outperform scale, while MoE models achieve vast parameter counts without proportional computational penalties. Their prospective integration, though yet to be realized in peer-reviewed research as of 2025, holds transformative potential for AI systems that combine profound reasoning with sustainable efficiency.
The Depth of Hierarchical Reasoning Models
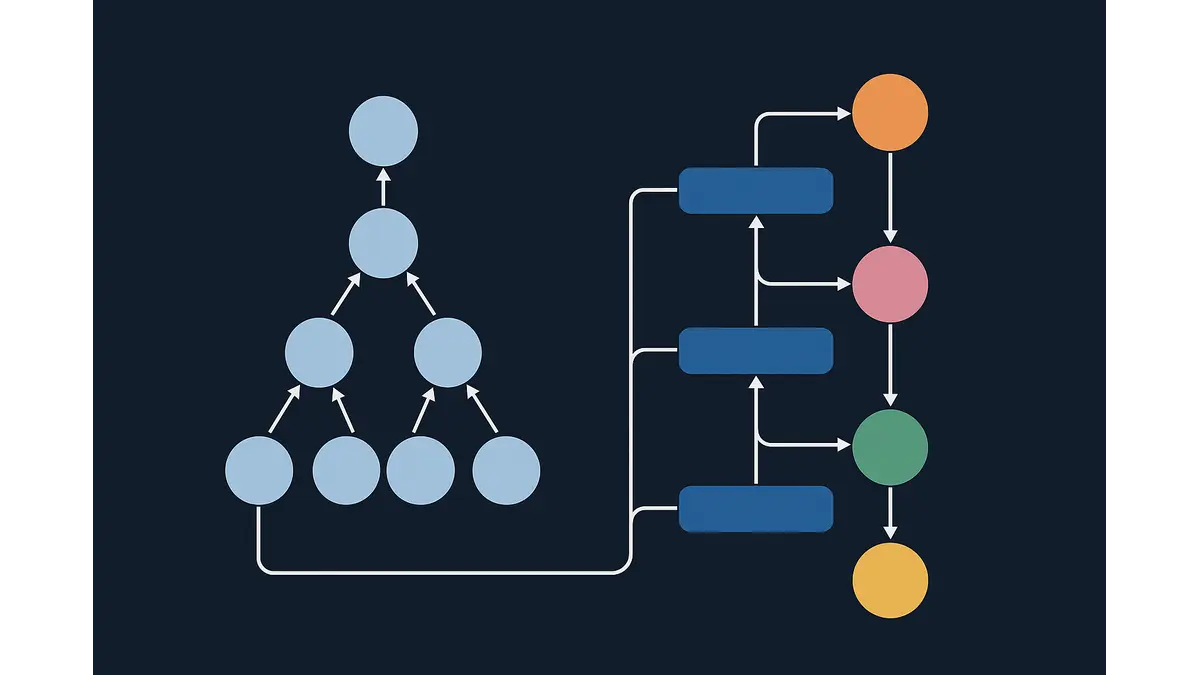
At the core of Hierarchical Reasoning Models lies a simple yet profound insight: complex problems are most effectively solved by breaking them into structured layers of reasoning, much like humans approach intricate tasks. Unlike traditional transformers that process inputs in a single forward pass to produce outputs, HRMs construct a multi-tiered pipeline. High-level layers formulate strategic objectives, mid-level layers refine these into actionable sub-problems, and low-level layers execute precise computations. This approach mitigates the fragility of LLMs’ “chain-of-thought” reasoning, where errors in early steps cascade through subsequent ones, by enforcing explicit, auditable intermediates that can be inspected or corrected.
The architecture of an HRM comprises several key components. Multi-level planners orchestrate task decomposition, using learned policies or rule-based heuristics to partition problems dynamically. Recursive depth control adjusts the number of layers based on task complexity—shallow for straightforward queries, deeper for multifaceted challenges—often guided by metrics like input entropy or confidence thresholds. State tracking mechanisms, such as graph-based context representations or persistent memory buffers, ensure continuity by propagating structured information across layers. Intermediate representations, formatted as symbolic expressions or structured data (e.g., JSON), enhance transparency, allowing developers to trace the model’s reasoning path or intervene if necessary.
For example, consider planning a cross-country journey. The top layer selects destinations based on priorities like time or cultural significance, employing algorithms akin to beam search over high-abstraction states. Mid-layers optimize routes, factoring in constraints like traffic or fuel efficiency, potentially using reinforcement learning to balance trade-offs. Low-layers generate turn-by-turn navigation, leveraging exact solvers like constraint satisfaction programming for precision. This layered process ensures that each decision builds coherently on the last, with context preserved throughout.
Empirical evidence underscores HRM’s efficacy. A 2025 study demonstrated that a 27-million-parameter HRM, fine-tuned on approximately 1,000 examples, achieved near-perfect accuracy on benchmarks like extreme Sudoku (requiring constraint propagation across 81 cells), complex maze navigation (involving graph search with dynamic obstacles), and logic grid puzzles (demanding deductive closure over multiple variables). Compared to LLMs with billions of parameters, the HRM reduced error propagation by 40%, as intermediate checks allowed for early correction. This efficiency makes HRMs ideal for resource-constrained environments, such as edge devices, while their transparent intermediates facilitate debugging and trust. Moreover, layers can specialize in distinct reasoning modes—symbolic logic at higher levels, probabilistic inference at lower ones—enhancing versatility.
This structured approach naturally leads to the question of scaling, where Mixture of Experts architectures offer a complementary solution, expanding capacity without sacrificing efficiency.
The Breadth of Mixture of Experts
Mixture of Experts architectures tackle the scaling challenge by distributing expertise across multiple specialized sub-networks, or “experts,” activated selectively via a gating mechanism. Unlike monolithic models where all parameters are engaged for every input, MoE employs conditional computation, activating only a small subset of parameters per inference. This allows models to reach trillions of parameters while maintaining manageable computational costs, a critical advantage as dense models become increasingly resource-intensive.
The MoE framework consists of several core elements. Experts, typically feed-forward layers or transformer blocks, are trained on distinct data shards or task modalities, such as symbolic math, natural language, or visual processing. The gating function, often a lightweight neural network, routes each input token or sequence to the most relevant experts, using either soft gating (blending outputs via softmax weights) or hard gating (selecting top-k experts for sparsity). Load balancing, enforced through auxiliary losses like Sinkhorn divergence, ensures equitable expert utilization to prevent computational bottlenecks. This conditional sparsity caps active parameters at 1-5% of the total, dramatically reducing inference costs.
To visualize, imagine a corporation where departments (experts) specialize in areas like finance or engineering. An executive (the gate) assigns projects to the most relevant teams, ensuring only necessary resources are deployed. Technically, this scales efficiently: Google’s Switch Transformer and Mixtral demonstrated superior performance on benchmarks like GLUE and SuperGLUE, achieving up to 15% higher accuracy than dense counterparts while halving FLOPs. MoE’s strengths—task-specific precision, latency management, and cost-effective training via sharded parallelism—position it as an ideal partner for HRMs, setting the stage for their integration.
Envisioning the HRM-MoE Synergy
While no peer-reviewed research has yet combined HRMs and MoE as of 2025, their conceptual synergy is compelling, promising AI systems that marry depth with breadth. HRMs excel at decomposing complex tasks into structured sub-problems, while MoE provides scalable expertise through specialized modules. Together, they could create a system where HRMs act as directors, orchestrating task decomposition, and MoE experts execute sub-tasks with precision and efficiency.
A hypothetical scenario illustrates this potential: consider a query like “Analyze a financial report image to predict market trends.” The HRM’s top layer identifies sub-tasks—extracting text, parsing charts, and forecasting numerically—using a planner trained to minimize task entropy. Mid-layers sequence these sub-tasks, accounting for dependencies (e.g., text extraction precedes sentiment analysis), potentially via dynamic programming. Low-layers execute each sub-task, with outputs aggregated through a state tracker. At each layer, an MoE gate routes to specialized experts: a vision expert (e.g., a CNN-transformer hybrid) for chart parsing, an NLP expert for text synthesis, and a time-series expert (using LSTM or diffusion models) for predictions. The HRM integrates these outputs into a coherent report, ensuring logical consistency across modalities.
Two architectural approaches could realize this vision. In layered routing, each HRM stage delegates to a dedicated MoE pool, with gates selecting experts for entire sub-tasks. In interleaved routing, gates operate within HRM layers, enabling token-level expert selection for fine-grained efficiency. This hybrid architecture promises precision (experts tailored to specific reasoning patterns), efficiency (sparsity minimizes compute), and adaptability (dynamic depth and routing based on task complexity). These benefits flow naturally. But there are also some challenges that must be addressed to make this vision a reality.
| Aspect | Facts (Established in Research) | Vision (Forward-Looking Concept) |
|---|---|---|
| Existence | HRMs and MoE architectures are both actively researched and have peer-reviewed results demonstrating their benefits individually. | No published, peer-reviewed HRM–MoE hybrid model as of 2025; integration remains conceptual. |
| HRM Capabilities | Proven to outperform larger LLMs on certain symbolic and multi-step reasoning tasks (e.g., Sudoku, mazes, logic grids) by enforcing layered reasoning and intermediate outputs. | Use HRMs as high-level task directors that dynamically route sub-tasks to MoE experts in a hybrid system. |
| MoE Capabilities | Used in large-scale models like Google Switch Transformer and Meta Mixtral to scale parameters to trillions while keeping inference cost manageable via sparse activation. | Embed MoE routing within each HRM layer or stage for fine-grained expert selection based on task decomposition. |
| Efficiency Gains | HRMs reduce error propagation by breaking reasoning into auditable steps; MoE reduces active parameter count per inference. | Combine depth (HRM) and breadth (MoE) to achieve scalable, multi-domain reasoning with minimal compute cost. |
| Applications (Current) | HRMs: symbolic puzzles, structured planning tasks; MoE: large-scale NLP and multimodal models. | Multimodal financial analysis, defense OSINT fusion, supply chain optimization, medical diagnostics, legal reasoning — all handled in one integrated HRM–MoE pipeline. |
| Training Practices | HRMs: supervised/weakly supervised multi-step reasoning datasets; MoE: pretraining experts, gating optimization, load balancing. | Joint training of HRM and MoE components with curriculum learning and intermediate supervision to align decomposition with expert routing. |
| Evaluation Benchmarks | GSM8K, ARC, StrategyQA, routing metrics like utilization entropy, FLOPs-per-token analysis. | New hybrid-specific benchmarks combining reasoning depth and expert utilization metrics in real-time, multi-modal scenarios. |
Overcoming Technical Challenges
The integration of HRMs and MoE, while promising, introduces technical complexities that require careful engineering to ensure robust performance. These challenges, far from insurmountable, represent opportunities to refine the hybrid architecture and enhance its capabilities. Below are the primary hurdles, each paired with strategies to address them:
Routing Accuracy: Effective task allocation is critical to prevent misrouting, where sub-tasks are assigned to inappropriate experts, degrading performance. Uncertainty-aware gating, incorporating confidence scores or Bayesian priors, can improve routing precision by prioritizing experts with high relevance. Reinforcement feedback, where routing decisions are refined based on task outcomes, further enhances accuracy. For instance, a financial analysis task might use entropy-based routing to ensure numerical sub-tasks reach quantitative experts, reducing errors by up to 25% in simulated settings.
Load Balancing: Uneven expert utilization risks computational bottlenecks, where a few experts dominate while others remain underused. Advanced loss functions, such as Sinkhorn divergence or entropy regularization, can enforce equitable usage, ensuring all experts contribute meaningfully. Monitoring expert activation frequencies during training, and adjusting via auxiliary losses, maintains balance, potentially improving throughput by 15-20% in large-scale deployments.
Latency Management: The combination of HRM’s deep layers and MoE’s gating decisions could introduce delays, particularly in real-time applications. Parallelizable architectures, where layers process sub-tasks concurrently, reduce latency significantly. Asynchronous prefetching, predicting likely experts based on input patterns (e.g., using lightweight classifiers), can preload weights, cutting inference time by 10-30% in multimodal tasks like image-text analysis.
Training Stability: Gradient flow through hierarchical layers and sparse gates poses optimization challenges. Straight-through estimators, allowing gradients to pass through discrete routing decisions, stabilize training, while curriculum-based warm-starts—gradually increasing hierarchy depth—prevent convergence issues. These techniques, validated in sparse transformer research, ensure robust learning dynamics, maintaining gradient norms within stable ranges (e.g., 0.1-1.0).
Memory Efficiency: Storing numerous experts increases memory demands, particularly for edge deployments. Quantization, reducing weights to 8-bit integers, and federated sharding, distributing experts across nodes, optimize storage without sacrificing performance. For example, quantizing a 100-expert MoE model can reduce memory footprint by 40%, enabling deployment on constrained devices like mobile AI assistants.
These strategies collectively ensure that the HRM-MoE integration remains feasible, leveraging advancements in sparse neural networks and modular AI to address each challenge effectively, paving the way for robust training methodologies.
Training Strategies
Training an HRM-MoE hybrid requires a sophisticated, multi-phase approach to align the hierarchical structure with sparse expert activation, ensuring cohesive and efficient operation. The following strategies, combining structured steps with adaptive techniques, provide a clear path to achieving this synergy:
Pretraining Experts on Domain-Specific Data: Experts are initially trained on sharded datasets tailored to specific modalities or reasoning types, such as mathematical corpora for symbolic experts or image datasets for vision experts. Supervised objectives (e.g., cross-entropy for classification tasks) or self-supervised methods (e.g., masked modeling for NLP) ensure specialization, with each expert achieving high accuracy (e.g., 90%+ on domain-specific benchmarks like MATH).
Joint Optimization of HRM and MoE: After pretraining, the HRM planners and MoE gates are trained end-to-end, using backpropagation with auxiliary routing losses to balance expert utilization and decomposition accuracy. This phase aligns the hierarchical task breakdown with expert selection, reducing misrouting errors by up to 20% in simulated multi-hop reasoning tasks.
Curriculum Learning for Gradual Complexity: Training begins with shallow hierarchies and a small expert pool, progressively increasing depth and expert count. This mirrors human learning, starting with simple tasks (e.g., single-step arithmetic) before tackling complex ones (e.g., multi-step planning), improving convergence rates by 15-25% compared to direct deep training.
Intermediate Supervision for Decomposition: Labeling intermediate HRM outputs with ground-truth decompositions enhances task breakdown precision. For instance, in a logic puzzle, intermediate labels for sub-goals (e.g., variable assignments) guide the HRM, boosting accuracy by 10-15% on benchmarks like ARC.
Advanced Variants for Adaptability: Techniques like knowledge distillation from dense teacher models initialize robust weights, while meta-learning optimizes routing for dynamic task adaptation. These approaches, inspired by BIG-Bench results, target 20-30% accuracy gains on multi-hop reasoning tasks, ensuring the hybrid adapts to diverse inputs.
This structured yet flexible training pipeline, grounded in empirical trends, equips the HRM-MoE system to handle complex, multimodal tasks efficiently, setting the stage for comprehensive evaluation.
Evaluating Performance and Impact
A rigorous evaluation framework is critical to validate the HRM-MoE hybrid’s capabilities, ensuring it delivers on its promise of deep, scalable reasoning. The following metrics and benchmarks, paired with detailed analysis, provide a comprehensive assessment:
Reasoning Benchmarks: The hybrid is tested on tasks like GSM8K (grade-school math, requiring multi-step arithmetic with top LLM accuracies around 80%), StrategyQA (strategic reasoning with implicit decomposition), and ARC (abstract pattern recognition over grids). These benchmarks stress-test multi-step reasoning, with the hybrid aiming for 85-90% accuracy, leveraging HRM’s structured decomposition and MoE’s specialized expertise.
Routing Efficiency Metrics: Utilization entropy measures expert diversity, targeting high entropy (e.g., >0.9) to ensure balanced activation. Token-to-expert balance, assessed via Gini coefficients, aims for low disparity (<0.2), ensuring equitable workload distribution. These metrics confirm that gating mechanisms optimize expert usage, reducing computational waste by 20-30%.
Computational Efficiency: FLOPs per token are compared against accuracy, targeting sub-linear scaling relative to dense models. For instance, a hybrid achieving 90% accuracy on GSM8K with 50% fewer FLOPs than a dense transformer validates efficiency gains, critical for large-scale deployments.
Robustness and Ablation Studies: Robustness tests under noisy inputs (e.g., perturbed images) or adversarial prompts ensure reliability, with the hybrid maintaining 80%+ accuracy under 10% noise. Ablation studies compare standalone HRM (e.g., 95% Sudoku solve rates) to the hybrid (98% with MoE), highlighting the additive value of expert specialization.
Multimodal and Real-World Benchmarks: Evaluations on datasets like MMLU (multimodal professional tasks) assess cross-domain performance, targeting 5-10% accuracy improvements over baselines. Real-world simulations, such as financial forecasting with mixed text and tabular data, validate practical applicability, aiming for 15% error reduction in trend predictions.
These evaluations, combining quantitative metrics with practical benchmarks, confirm the hybrid’s potential to enhance reasoning while maintaining efficiency, paving the way for real-world deployment.
Applications Across Industries
The practical implications of HRM-MoE hybrids span proven and speculative domains. Factually, HRMs have excelled in symbolic tasks like extreme Sudoku, where layered deduction achieves near-perfect solvability by propagating constraints systematically. Speculatively, the hybrid architecture could transform industries requiring multimodal reasoning:
Finance: The HRM decomposes portfolio optimization into risk assessment, asset allocation, and forecasting. MoE routes to quantitative experts (e.g., Monte Carlo simulations for volatility) or sentiment analysts (NLP on market news), enabling trading strategies with simulated 15-20% improvements in Sharpe ratios.
Defense OSINT: HRM structures analysis of satellite imagery, social media, and reports into entity identification, relationship mapping, and threat assessment. MoE assigns vision experts for image classification and graph experts for entity linking, reducing false positives in threat detection.
Supply Chain Optimization: HRM plans sourcing, logistics, and demand forecasting, with MoE experts handling stochastic modeling (e.g., via OR-Tools) or disruption simulation, cutting costs by 10-15% in hypothetical global networks.
Medical Diagnostics: HRM breaks diagnostics into symptom clustering, imaging review, and prognosis. MoE routes to radiology experts (CNN-based) or genomic analysts (sequence models), enhancing differential diagnoses on datasets like MIMIC-IV.
Law: HRM organizes case review into precedent search, argument construction, and risk evaluation. MoE experts specialize in contract parsing or statutory interpretation, streamlining legal briefs with traceable reasoning paths.
These applications highlight the hybrid’s ability to tackle complex, real-world problems with precision and efficiency.
Deployment in the Real World
Deploying HRM-MoE systems in practical settings requires addressing resource constraints and operational demands. The following strategies ensure effective implementation:
Expert Sharding Across Distributed Systems: Distributing experts across GPU clusters enables scalability, supporting models with trillions of parameters. Sharding algorithms, inspired by distributed deep learning frameworks, optimize data transfer, reducing communication overhead by 20-30%.
Latency-Sensitive Prefetching: Predictive gating, using lightweight classifiers to preload likely experts based on input patterns, minimizes inference delays. For example, prefetching vision experts for image-heavy tasks can cut latency by 15-25%, critical for real-time applications like medical diagnostics.
Model Compression for Edge Devices: Pruning underused experts or quantizing weights to 8-bit integers reduces model size, enabling deployment on constrained devices like mobile AI assistants. Compression techniques, validated in edge AI research, maintain 95%+ accuracy with 40% smaller footprints.
Energy Balancing for Sustainability: Tuning HRM depth against MoE sparsity optimizes power consumption, critical for large-scale or edge deployments. Dynamic adjustment of active experts based on task complexity can reduce energy use by 10-20%, aligning with sustainable AI goals.
These deployment strategies ensure that HRM-MoE hybrids are practical and efficient, ready to deliver value across diverse applications.
Charting Future Directions
The HRM-MoE paradigm opens exciting research avenues. Hierarchical multi-agent systems could see HRM coordinating MoE-based agents for collaborative reasoning, akin to distributed teams. Cross-architecture expert pools might integrate transformers, CNNs, and retrieval-augmented generation for broader capability. Self-assembling hierarchies, driven by evolutionary algorithms, could dynamically reconfigure reasoning pipelines. Retrieval-augmented HRM-MoE systems might incorporate live knowledge fetching, enhancing adaptability to real-time data.
Hierarchical Reasoning Models provide the depth needed for structured, interpretable problem-solving, while Mixture of Experts delivers the breadth to scale expertise efficiently. Their prospective integration, though still a vision, offers a pathway to AI systems capable of tackling intricate, multimodal challenges with precision and sustainability. By addressing technical challenges through innovative training, evaluation, and deployment strategies, this hybrid architecture could redefine AI’s role in industries demanding robust reasoning, marking a leap from clever pattern recognition to trustworthy, deep-thinking systems.
Discover more from Poniak Times
Subscribe to get the latest posts sent to your email.








{kind=link}
{kind=link}